
I study at EPITA, a French computer science engineering school where a large part of the curriculum is built around hands-on programming, Unix systems, and building software that actually runs under real constraints. This page is a high-level map of the kind of work I do there: not a syllabus, but the stack of ideas and tools that keep showing up when I write a daemon in C, debug a Java service, or chase a packet across a network.
When I need a place to park exact commands or notes on Linux and tooling, I use my memo site at memos.godef.be. Think of it as the lab notebook; this page is the story that ties the notebooks together.
EPITA starts with an intensive C immersion usually called the pool: short deadlines, peer review, and daily progress checks. The goal is not clever tricks but mechanical correctness under pressure: clean compilation with strict flags, consistent style, tests that actually fail when they should, and the habit of reading man pages before guessing. Exams later reuse the same expectations at a higher pace, so the pool is really training for predictable engineering.
I rebuilt several foundational projects myself to own the details: a minimal
make clone (minimake), a dynamic allocator backed by mmap instead of the
libc heap (malloc), and a small archiver that understands the USTAR layout named
epitar. Each project forces the same lesson in a different shape: alignments,
padding, lifetime rules, and error paths that do not leak memory or file descriptors. When the compiler and
Valgrind agree, you know you are finally managing memory instead of hoping the runtime will forgive you.
The through-line is deliberately low-level: the ABI and the linker stay visible, there is no hidden magic beyond what I mapped myself, and every allocation has an owner. That mindset is what later systems work builds on.
gdb recipes, and toolchain notes usually end up on
memos.godef.be once I have battle-tested them.
gcc -std=c11 -Wall -Wextra -Werror -g -fsanitize=address,undefined main.c -o main
Systems lectures and labs are not only about calling POSIX functions: they walk you through reimplementing the tools
you already rely on so the file formats and kernel protocols stop being black boxes. A major thread is rebuilding a
mini gdb (my_db): the same user-visible behaviour on a reduced command set,
backed by the same ideas the real debugger uses under the hood. Along the way you read the official
gdb documentation, compare traces side by side with GNU gdb, and learn why debug info exists
at all instead of treating “step” as a single indivisible opcode.
my_db and gdb through my_nm and my_strace
my_db forced me into DWARF: compile units, DIE trees, attribute encodings, and
especially line number programs so a program counter can be mapped back to a source file and line. I learned how
gcc -g emits .debug_info, .debug_line, .debug_abbrev, and friends,
how those sections tie to the executable’s code segment, and why breakpoints land on instruction boundaries rather than
on C tokens. Breakpoint insertion, single stepping with respect to signals, stack unwinding, and memory inspection all
became exercises in reading specs and matching the reference gdb when my register dumps disagreed with
my expectations.
my_nm is the static counterpart: the course drives everything through the ELF
specification. I started with identification - magic bytes 0x7f ELF, values in e_ident such as
EI_CLASS (32-bit versus 64-bit), EI_DATA (endianness), and EI_OSABI - so I could
reject a non-ELF or decide how to parse the rest. Then I walked the program header table for segments, the section
header table for .symtab / .dynsym, relocation entries, and symbol binding and type flags
(STB_*, STT_*) until listing symbols is just structured table walking. Once that clicks,
“where does this label live?” is no longer opaque tooling but a layout you can draw on paper.
my_strace widens the lens to dynamics: attach to a tracee, stop at syscall boundaries, decode
arguments and errno on return, and rebuild a timeline of kernel interactions without the original binary doing the work
for me. Together the three projects connect the same machine from three distances: full interactive debugging with
DWARF, ELF layout and symbols, and the syscall boundary.
Practically, I lived inside gdb while validating each milestone: watchpoints on structure fields,
scripted breakpoint commands, and disassembly whenever the ABI stopped matching my expectations. The memos site holds
the exact command sequences I reuse when I forget the syntax for the tenth time.
I am currently working on grootkit, a theoretical systems project for SYS2: it is
meant for controlled lab machines and coursework documentation, not for sneaking onto real networks. The on-host
piece is a Linux kernel module written in C, built with the kernel’s kbuild machinery, which produces a
.ko I can load with insmod on a compatible kernel version. Kernel modules are tightly
coupled to the ABI (Application binary interface) of a given tree, so the project tracks which kernel versions the code is known to build against and
treats anything else as unsupported until ported.
The module is only half of the story. The other half is an infrastructure layer: a command and control style server that centralises agents, plus fleet or “park” management so I can reason about many lab hosts instead of one. Traffic is shaped through a bounce entry point implemented as a reverse proxy and TCP forwarding path (HAProxy in front of the C2 server), which keeps a single public listener while the real services sit behind it and can be swapped or filtered without recompiling the agent. The architecture is intentionally close to real incident-response training setups: explicit network layout, reproducible VMs, and CI that builds the module against pinned kernel headers so regressions show up before you boot a machine.
After C, EPITA runs a shorter Java intensive called an atelier: same spirit as the pool (short exercises, strict deadlines, lots of feedback) but aimed at the JVM ecosystem and a lot lighter than the real piscine, build tools, and idiomatic object-oriented design instead of manual memory. I learned to lean on the compiler for type structure, on the test runner for regressions, and on the standard library instead of reinventing containers.
The architectural pattern we were asked to internalise for enterprise-style work is a classic layered architecture: a presentation boundary that speaks HTTP and JSON, a domain layer that encodes use cases and business rules, and a data layer that maps objects to tables. Converters sit between presentation DTOs and domain entities so REST shapes do not leak into the core model. On the implementation side that maps cleanly to Jakarta REST (JAX-RS) resources, injectable services, and JPA entities with repositories - in my case on top of Quarkus so dependency injection, persistence, and dev-mode reload all come from one supported stack.
The large graded exercise for the Java Web Services module is Yakamon: a game-like HTTP API where a player starts a session on a chosen map, then interacts through dedicated resources for state and moves. AND I LOVED IT SOOOO MUCHHH!!!!. The interesting engineering work is not the gimmick but the discipline - transactional boundaries when the world state changes, validation at the edge, and keeping the domain rules testable without starting an HTTP server for every assertion. Maven coordinates the build; Quarkus runs the show at runtime; the memos site still holds the curl snippets and database URLs I use when switching machines.
I had already seen most of the classic stack at HELMo, so in EPITA’s network track I focus on what find interresting. I'm doings some labs work in GNS3 for routing, DHCP, and DNS.
A stable link-local address under fe80::/10 often comes straight from the interface’s
48-bit MAC through modified EUI-64: split the MAC into its upper three octets and lower three octets,
insert ff:fe in the middle, then flip the universal/local bit (the second-least-significant
bit of the first octet) as required by RFC 4291 so the 64-bit interface identifier is valid on the wire. The
result is an address that looks opaque at first glance but is completely reproducible from the card which matters
for scanning, neighbour caches, and reasoning about privacy extensions when they are turned off.
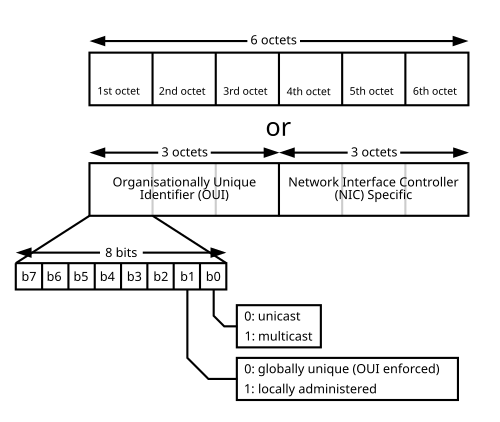
The least significant bit of the first octet is the I/G (individual/group) flag:
0 means the frame is addressed to one station (unicast at the Ethernet level), 1 means
multicast. The next bit is the U/L (universal/local) flag: 0 means the
address follows a globally assigned OUI (Organizationally Unique Identifier) from the manufacturer, 1 means it was chosen locally (for example
by a hypervisor or by hand). Those two bits are enough to sanity-check whether an address “should” behave as a unicast
NIC, a multicast group, or a locally administered virtual interface before I even open the IPv4 or IPv6 header.
Beyond vendor OUIs, several prefixes are reserved or widely recognised. The table is a cheat sheet I keep in mind when a capture shows traffic I did not explicitly configure.
| Pattern | Role |
|---|---|
FF:FF:FF:FF:FF:FF |
Layer-two broadcast |
01:00:0C:CC:CC:CC |
Cisco Discovery Protocol (CDP) |
01:80:C2:00:00:00 |
IEEE spanning tree (STP) group address |
33:33:xx:xx:xx:xx |
IPv6 multicast mapped from multicast groups (33:33 plus the low 32 bits of the IPv6 group) |
01:00:5E:xx:xx:xx |
IPv4 multicast on Ethernet (01-00-5E / 23 low bits of the IPv4 multicast address) |
00:00:0C:07:AC:xx |
Cisco HSRP virtual MAC (group in the last nibble) |
00:00:5E:00:01:xx |
VRRP virtual router MAC (xx is the virtual router ID) |
ip -6 addr show
ip neigh showI write a careful C module on Monday, untangle a Java stack trace on Tuesday, and explain a TCP capture on Wednesday. The technologies look different on the surface, but I repeat the same habits: I read the specification, I write the smallest program that reproduces the issue, I measure before optimising, and I document the assumptions I baked into the code.
I keep this public site intentionally light on assignment-specific detail and heavy on durable concepts. For anything that looks like a cheat sheet, the honest home is still memos.godef.be, where I can iterate quickly without tripping over coursework redistribution rules.